で計算してみましょうMSエクセル標本分散と標準偏差。 分散も計算してみましょう 確率変数分布がわかっている場合。
まずは考えてみましょう 分散、 それから 標準偏差.
サンプルの分散
サンプルの分散 (標本分散、サンプル分散) は、 を基準とした配列内の値の広がりを特徴付けます。
3 つの式はすべて数学的に等価です。
最初の式から明らかなように、 標本分散配列内の各値の偏差の二乗の合計です。 平均から、サンプルサイズから 1 を引いた値で割ります。
差異 サンプル DISP() 関数が使用されます (英語)。 VAR という名前、つまり 分散。 MS EXCEL 2010 バージョン以降は、アナログの DISP.V() (英語) を使用することをお勧めします。 VARS という名前、つまり サンプルの分散。 また、MS EXCEL 2010 のバージョンからは、DISP.Г() という関数が英語で追加されました。 VARP という名前、つまり Population VARiance: を計算します。 分散のために 人口 。 違いはすべて分母にあります。DISP.V() のような n-1 ではなく、DISP.G() の分母は n だけです。 MS EXCEL 2010 より前は、母集団の分散を計算するために VAR() 関数が使用されていました。
サンプルの分散
=QUADROTCL(サンプル)/(COUNT(サンプル)-1)
=(SUM(サンプル)-COUNT(サンプル)*AVERAGE(サンプル)^2)/(COUNT(サンプル)-1)– 通常の式
=SUM((サンプル -AVERAGE(サンプル))^2)/ (COUNT(サンプル)-1) –
サンプルの分散すべての値が互いに等しく、したがって等しい場合にのみ、0 に等しくなります。 平均値。 通常、値が大きいほど 差異、配列内の値の広がりが大きくなります。
サンプルの分散点推定値です 差異作成された確率変数の分布 サンプル。 工事について 信頼区間 評価するとき 差異記事内で読むことができます。
確率変数の分散
計算するには 分散確率変数、それを知る必要があります。
のために 差異確率変数 X は、Var(X) と表記されることがよくあります。 分散平均値からの偏差の二乗に等しい E(X): Var(X)=E[(X-E(X)) 2 ]
分散次の式で計算されます。

ここで、x i は確率変数が取り得る値、μ は平均値 ()、p(x) は確率変数が値 x を取る確率です。
確率変数に がある場合、 分散次の式で計算されます。

寸法 差異元の値の測定単位の 2 乗に相当します。 たとえば、サンプル内の値が部品の重量測定値 (kg) を表す場合、分散次元は kg 2 になります。 これは解釈が難しい場合があるため、値の広がりを特徴付けるには、次の値の平方根に等しい値を使用します。 差異 – 標準偏差.
いくつかのプロパティ 差異:
Var(X+a)=Var(X)、ここで、X は確率変数、a は定数です。
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
この分散特性は、 線形回帰に関する記事.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y)、ここで X と Y は確率変数、Cov(X;Y) はこれらの確率変数の共分散です。
確率変数が独立している場合、それらは 共分散は 0 に等しいため、Var(X+Y)=Var(X)+Var(Y) となります。 この分散の性質は導出に使用されます。
独立した量の場合、Var(X-Y)=Var(X+Y) であることを示してみましょう。 実際、Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y)。 この分散特性は を構築するために使用されます。
サンプル標準偏差
サンプル標準偏差は、サンプル内の値がその に比べてどの程度広く分散しているかを示す尺度です。
A優先、 標準偏差の平方根に等しい 差異:

標準偏差の値の大きさは考慮されません。 サンプル、ただし周囲の価値観の分散の度合いだけ 平均。 これを説明するために、例を挙げてみましょう。
2 つのサンプル (1; 5; 9) と (1001; 1005; 1009) の標準偏差を計算してみましょう。 どちらの場合も、s=4 です。 サンプルの配列値に対する標準偏差の比率が大きく異なることが明らかです。 このような場合に使用されるのが、 変動係数(変動係数、CV) - 比率 標準偏差平均に 算術、パーセンテージで表されます。
MS EXCEL 2007 以前のバージョンの計算用 サンプル標準偏差関数 =STDEVAL() が使用されます (英語)。 STDEV という名前を付けます。 標準偏差。 MS EXCEL 2010 のバージョン以降は、英語版の =STANDDEV.B() を使用することをお勧めします。 STDEV.S という名前を付けます。 サンプル標準偏差。
また、MS EXCEL 2010 のバージョンからは、関数 STANDARDEV.G() (英語) が追加されました。 STDEV.P という名前、つまり 人口標準偏差: を計算します。 標準偏差のために 人口。 違いはすべて分母にあります。STANDARDEV.V() のような n-1 の代わりに、STANDARDEVAL.G() の分母には n だけが含まれます。
標準偏差以下の式を使用して直接計算することもできます (サンプル ファイルを参照)
=ROOT(QUADROTCL(サンプル)/(COUNT(サンプル)-1))
=ROOT((SUM(サンプル)-COUNT(サンプル)*AVERAGE(サンプル)^2)/(COUNT(サンプル)-1))
散乱のその他の尺度
SQUADROTCL() 関数は次のように計算します。 値からの偏差の二乗の合計 平均。 この関数は、数式 =DISP.G( と同じ結果を返します。 サンプル)*チェック( サンプル) 、 どこ サンプル- サンプル値の配列を含む範囲への参照 ()。 QUADROCL() 関数の計算は次の式に従って行われます。

SROTCL() 関数は、データ セットの広がりの尺度でもあります。 関数 SROTCL() は、値の偏差の絶対値の平均を計算します。 平均。 この関数は数式と同じ結果を返します。 =SUMPRODUCT(ABS(サンプル-AVERAGE(サンプル)))/COUNT(サンプル)、 どこ サンプル- サンプル値の配列を含む範囲へのリンク。
関数 SROTCL () の計算は次の式に従って行われます。

統計のばらつきは、特性の 2 乗の個別値として求められます。 初期データに応じて、単純な重み付き分散公式を使用して決定されます。
1. (グループ化されていないデータの場合) は次の式を使用して計算されます。
2. 加重分散 (変動系列の場合):
 ここで、n は周波数 (係数 X の再現性) です。
ここで、n は周波数 (係数 X の再現性) です。
分散を求める例
このページでは説明します 標準的な例分散を見つけるには、他の問題を調べて分散を見つけることもできます
例 1. 次のデータは、20 人の通信制学生のグループで利用できます。 構築する必要がある 間隔シリーズ特性の分布、特性の平均値を計算し、その分散を調査します。
 間隔グループを作成しましょう。 次の式を使用して間隔の範囲を決定しましょう。
間隔グループを作成しましょう。 次の式を使用して間隔の範囲を決定しましょう。
![]() ここで、X max はグループ化特性の最大値です。
ここで、X max はグループ化特性の最大値です。
X min – グループ化特性の最小値。
n – 間隔の数:
n=5 を受け入れます。 ステップは次のとおりです: h = (192 - 159)/ 5 = 6.6
間隔グループを作成しましょう
 さらに計算を行うために、補助テーブルを作成します。
さらに計算を行うために、補助テーブルを作成します。
 X'i は間隔の真ん中です。 (たとえば、間隔の中央 159 – 165.6 = 162.3)
X'i は間隔の真ん中です。 (たとえば、間隔の中央 159 – 165.6 = 162.3)
加重算術平均の式を使用して生徒の平均身長を決定します。
 次の式を使用して分散を求めてみましょう。
次の式を使用して分散を求めてみましょう。
分散公式は次のように変形できます。
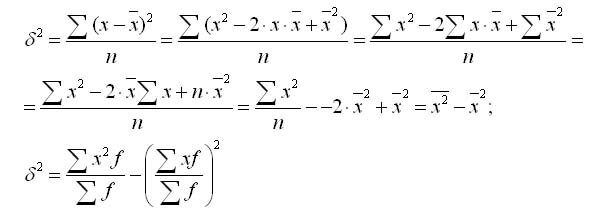
この式から次のことがわかります 分散は次の値に等しい オプションの二乗の平均と二乗と平均の差。
の差異 バリエーションシリーズ モーメント法を使用した等間隔の計算は、分散の 2 番目のプロパティ (すべてのオプションを間隔の値で割る) を使用して次の方法で計算できます。 分散の決定モーメント法を使用して計算され、次の式を使用する方が労力が少なくなります。

ここで、i は間隔の値です。
A は従来のゼロであり、最高周波数の間隔の中央を使用すると便利です。
m1 は 1 次モーメントの 2 乗です。
m2 - 二次モーメント
(統計的母集団において、相互に排他的な選択肢が 2 つだけになるように特性が変化する場合、そのような変動性は代替と呼ばれます) は、次の式を使用して計算できます。

で置き換える この式分散 q =1- p の場合、次のようになります。

差異の種類
合計差異変動を引き起こすすべての要因の影響下で、集団全体にわたる特性の変動を測定します。 偏差の二乗平均に等しい 個体値特徴 x は x の全体平均から求められ、単純分散または加重分散として定義できます。
ランダムな変動を特徴づけます。 変動の一部は説明されていない要因の影響によるものであり、グループの基礎を形成する要因属性には依存しません。 このような分散は、グループ X 内の属性の個々の値のグループの算術平均からの偏差の二乗平均に等しく、単純分散または加重分散として計算できます。
したがって、 グループ内分散測定グループ内の形質の変動であり、次の式で決定されます。

ここで、xi はグループ平均です。
ni はグループ内のユニットの数です。
たとえば、作業場での労働生産性のレベルに対する労働者の資格の影響を研究するタスクで決定する必要があるグループ内差異は、考えられるすべての要因(機器の技術的状態、設備の可用性)によって引き起こされる各グループの生産量の差異を示しています。工具や材料、労働者の年齢、労働強度など。)、資格カテゴリーの違いを除きます(グループ内ではすべての労働者が同じ資格を持っています)。
内部からの平均 グループの分散ランダム、つまり、グループ化要因を除く他のすべての要因の影響下で発生した変動の部分を反映します。 次の式を使用して計算されます。

グループの基礎を形成する因子記号の影響による、結果として得られる特性の系統的な変動を特徴付けます。 これは、全体の平均からのグループ平均の偏差の二乗平均に等しい。 グループ間分散は次の式を使用して計算されます。

統計に分散を加えるルール
によると 分散の追加ルール合計分散は、グループ内分散とグループ間分散の平均の合計に等しくなります。
![]()
このルールの意味すべての要因の影響下で生じる分散の合計は、他のすべての要因の影響下で生じる分散とグループ化要因によって生じる分散の合計に等しいということです。
分散を加算する公式を使用すると、2 つの既知の分散から 3 番目の未知の分散を求めることができ、グループ化特性の影響の強さを判断することもできます。
分散特性
1. 特性のすべての値が同じ一定量だけ減少(増加)した場合、分散は変化しません。
2. 特性のすべての値が同じ n 倍減少 (増加) した場合、分散はそれに対応して n^2 倍減少 (増加) します。
分散確率変数- 特定のスプレッドの尺度 確率変数、つまり彼女 逸脱から 数学的期待。 統計では、分散を表すために表記 (シグマ二乗) がよく使用されます。 に等しい分散の平方根は次のように呼ばれます。 標準偏差または標準スプレッド。 標準偏差は確率変数自体と同じ単位で測定され、分散はその単位の二乗で測定されます。
サンプル全体を推定するために 1 つの値 (平均値、最頻値、中央値など) だけを使用するのは非常に便利ですが、このアプローチは誤った結論につながりやすいです。 この状況の理由は、値自体にあるのではなく、1 つの値がデータ値の広がりをまったく反映していないという事実にあります。
たとえば、サンプルでは次のようになります。
平均値は5です。
ただし、サンプル自体には、値が 5 の要素は 1 つもありません。サンプル内の各要素がその平均値にどの程度近づいているかを知る必要がある場合があります。 言い換えれば、値の分散を知る必要があります。 データの変化の程度を知ることで、より適切に解釈できるようになります 平均値, 中央値そして ファッション。 サンプル値がどの程度変化するかは、分散と標準偏差を計算することで決定されます。
分散と 平方根標準偏差と呼ばれる分散の値は、サンプル平均からの平均偏差を特徴付けます。 これら 2 つの量のうち、 最高値それは持っています 標準偏差。 この値は、サンプルの中央の要素から要素までの平均距離と考えることができます。
分散を有意義に解釈するのは困難です。 ただし、この値の平方根は標準偏差であり、簡単に解釈できます。
標準偏差は、最初に分散を決定し、次に分散の平方根を取ることによって計算されます。
たとえば、図に示すデータ配列の場合、次の値が取得されます。

写真1
ここで、差の二乗の平均値は 717.43 です。 標準偏差を取得するには、この数値の平方根を取るだけです。
結果は約 26.78 になります。
標準偏差は、項目のサンプル平均からの平均距離として解釈されることに注意してください。
標準偏差は、平均がサンプル全体をどの程度よく説明しているかを測定します。
あなたが PC アセンブリ生産部門の責任者だとしましょう。 四半期報告書によると、前四半期の生産台数は 2,500 台でした。 これは良いことですか、それとも悪いことですか? このデータの標準偏差をレポートに表示するように要求しました (またはレポートにこの列がすでに存在しています)。 たとえば、標準偏差の数値は 2000 です。部門の責任者であるあなたにとって、生産ラインにはより適切な管理が必要であることが明らかです (組み立てられた PC の数の偏差が大きすぎます)。
標準偏差が大きい場合、データは平均値の周囲に広く分散し、標準偏差が小さい場合、データは平均値の近くに集中することを思い出してください。
4つの統計 DISP関数()、VAR()、STDEV()、および STDEV() – セル範囲内の数値の分散と標準偏差を計算するように設計されています。 一連のデータの分散と標準偏差を計算する前に、そのデータが母集団を表すのか母集団のサンプルを表すのかを判断する必要があります。 一般母集団からのサンプルの場合は関数 VAR() と STDEV() を使用し、一般母集団の場合は関数 VAR() と STDEV() を使用する必要があります。
| 人口 | 関数 |
 | DISPR() |
 | スタンドトロンプ() |
| サンプル | |
 | DISP() |
 | STDEV() |
分散 (および標準偏差) は、前述したように、データセットに含まれる値が算術平均の周囲にどの程度分散しているかを示します。
分散または標準偏差の値が小さい場合は、すべてのデータが算術平均の周囲に集中していることを示します。 非常に重要これらの値は、データが広範囲の値に分散していることを示しています。
分散を有意義に解釈するのは非常に困難です (小さい値、大きい値は何を意味するのでしょうか?)。 パフォーマンス タスク 3データセットの分散の意味をグラフ上に視覚的に表示できます。
タスク
· 演習 1.
· 2.1。 分散と標準偏差という概念を与えます。 統計データ処理の象徴的な名称です。
· 2.2. 図 1 に従ってワークシートに記入し、必要な計算を行います。
・2.3. 計算に使用される基本的な式を教えてください
· 2.4。 すべての指定 ( 、 、 ) について説明します。
・2.5。 説明する 実用的な重要性分散と標準偏差の概念。
タスク2。
1.1. 一般母集団とサンプルという概念を示します。 統計データ処理のための数学的期待値とその算術平均の記号的指定。
1.2. 図2に従ってワークシートを作成し、計算してください。
1.3. (一般母集団およびサンプルの) 計算に使用される基本的な式を提供します。

図2
1.4. サンプルで 46.43 や 48.78 などの算術平均値を取得できる理由を説明してください (付録ファイルを参照)。 結論を導き出します。
タスク3。
異なるデータセットを持つ 2 つのサンプルがありますが、それらの平均は同じになります。

図3
3.1. 図 3 に従ってワークシートに記入し、必要な計算を行います。
3.2. 基本的な計算式を教えてください。
3.3. 図 4、5 に従ってグラフを作成します。
3.4. 取得した依存関係を説明します。
3.5. 2 つのサンプルのデータに対して同様の計算を実行します。
オリジナルサンプル 11119999
2 番目のサンプルの算術平均が同じになるように 2 番目のサンプルの値を選択します。次に例を示します。

2 番目のサンプルの値を自分で選択します。 図 3、4、5 と同様の計算とグラフを並べます。計算で使用された基本的な式を示します。
適切な結論を導き出します。
必要なすべての画像、グラフ、数式、簡単な説明を含むレポートの形式ですべてのタスクを完了します。
注: グラフの構成については、図と簡単な説明を使用して説明する必要があります。
統計におけるばらつきを一般化する主な指標は、分散と平均です。 標準偏差.
分散これ 算術平均 全体の平均からの各特性値の二乗偏差。 分散は通常、偏差の二乗平均と呼ばれ、 2 で表されます。 ソース データに応じて、単純または加重算術平均を使用して分散を計算できます。
重み付けされていない (単純な) 分散。
 分散の重み付け。
分散の重み付け。
標準偏差 これは絶対サイズの一般化された特性です バリエーション 集合体のサイン。 これは、属性と同じ測定単位 (メートル、トン、パーセント、ヘクタールなど) で表されます。
標準偏差は分散の平方根であり、 で表されます。
 重み付けされていない標準偏差。
重み付けされていない標準偏差。
 加重標準偏差。
加重標準偏差。
標準偏差は、平均値の信頼性の尺度です。 標準偏差が小さいほど、算術平均は母集団全体をよりよく反映しています。
標準偏差の計算の前に、分散の計算が行われます。
加重分散を計算する手順は次のとおりです。
1) 加重算術平均を決定します。
2) 平均からのオプションの偏差を計算します。
3) 平均からの各オプションの偏差を二乗します。
4) 偏差の二乗に重み (度数) を掛けます。
5) 結果の生成物を要約します。
![]()
6) 結果の量を重みの合計で割ります。

例2.1

加重算術平均を計算してみましょう。

平均からの偏差の値とその二乗が表に示されています。 分散を定義しましょう。

標準偏差は次のようになります。

ソースデータが間隔の形式で表示される場合 配信シリーズ の場合は、まず属性の離散値を決定してから、説明されている方法を適用する必要があります。
例2.2
小麦収量に応じた集団農場の播種面積の分布に関するデータを使用して、区間系列の分散の計算を示します。

算術平均は次のとおりです。

分散を計算してみましょう。

6.3. 個別データに基づいた計算式による分散の計算
計算手法 差異 複雑で、オプションや頻度の値が大きいと面倒になる可能性があります。 分散の特性を利用して計算を簡略化できます。
分散液は次のような性質を持っています。
1. 変化する特性の重み (周波数) を特定の回数だけ減少または増加しても、分散は変化しません。
2. 特性の各値を同じ一定量ずつ増減します。 あ分散は変わりません。
3. 特性の各値を特定の回数だけ増減します。 kそれぞれ、分散を減少または増加させます k 2回 標準偏差 で k一度。
4. 任意の値に対する特性の分散は、平均値と任意の値の差の 2 乗あたりの算術平均に対する分散よりも常に大きくなります。
![]()
もし あ 0 の場合、次の等式が得られます。
つまり、特性の分散は、特性値の平均二乗と平均の二乗の差に等しくなります。
分散を計算する場合、各プロパティは独立して使用することも、他のプロパティと組み合わせて使用することもできます。
分散を計算する手順は簡単です。
1) 決定する 算術平均 :
2) 算術平均を二乗します。

3) シリーズの各バリアントの偏差を二乗します。
バツ 私 2 .
4) オプションの二乗和を求めます。
5) オプションの二乗和をその数で割ります。つまり、平均二乗を求めます。
6) 特性の平均二乗と平均の二乗の差を求めます。
例3.1労働者の生産性に関しては、次のデータが利用可能です。

次の計算をしてみましょう。
![]()
確率理論は、高等教育機関の学生のみが研究する数学の特別な分野です。 計算や公式は好きですか? 正規分布、アンサンブル エントロピー、数学的期待値、および離散確率変数の分散について知ることになると怖くないですか? そうすれば、この主題はあなたにとって非常に興味深いものになるでしょう。 この科学分野の最も重要な基本概念をいくつか理解しましょう。
基本を思い出しましょう
確率論の最も単純な概念を覚えていたとしても、記事の最初の段落を無視しないでください。 ポイントは、それがなければ、 明確な理解基本的には、以下で説明する数式を使用することはできません。
したがって、ランダムなイベントが発生し、実験が行われます。 私たちがとった行動の結果、いくつかの結果が得られます。そのうちのいくつかは頻繁に発生し、他のものはあまり発生しません。 イベントの確率は、ある種類の実際に得られる結果の数と、 総数可能。 この概念の古典的な定義を知っていなければ、連続確率変数の数学的期待値と分散を研究し始めることができます。
平均
学校に戻ると、数学の授業中に算術平均を扱い始めました。 この概念は確率論で広く使用されているため、無視することはできません。 現時点で私たちにとって重要なことは、確率変数の数学的期待値と分散の公式でこれに遭遇することです。

一連の数値があり、算術平均を求めたいと考えています。 私たちに必要なのは、利用可能なものをすべて合計し、シーケンス内の要素の数で割ることだけです。 1 から 9 までの数字を考えてみましょう。要素の合計は 45 になり、この値を 9 で割ります。答え: - 5。
分散
科学用語では、分散とは、算術平均から得られた特性値の偏差の平均二乗です。 それはラテン語の大文字 D で表されます。それを計算するには何が必要ですか? シーケンスの各要素について、既存の数値と算術平均の差を計算し、それを二乗します。 私たちが検討しているイベントの結果には、存在する可能性があるのと同じだけ多くの値が存在します。 次に、受け取ったものをすべて合計し、シーケンス内の要素の数で割ります。 考えられる結果が 5 つある場合は、5 で割ります。

分散には、問題を解決するときに使用するために覚えておく必要がある特性もあります。 たとえば、確率変数が X 倍増加すると、分散は X の 2 乗倍 (つまり X*X) 増加します。 彼女は決して起こらない ゼロ未満また、値を同じ値だけ上下にシフトすることに依存しません。 さらに、独立した試行の場合、合計の分散は分散の合計に等しくなります。
ここで、離散確率変数の分散と数学的期待の例を必ず考慮する必要があります。
21 回の実験を実行し、7 つの異なる結果が得られたとします。 それぞれを 1 回、2 回、2 回、3 回、4 回、4 回、5 回観察しました。 分散は何に等しくなりますか?
まず、算術平均を計算しましょう。もちろん、要素の合計は 21 です。それを 7 で割ると、3 が得られます。次に、元のシーケンス内の各数値から 3 を引き、各値を 2 乗し、結果を加算します。 結果は 12 です。あとは、数値を要素の数で割るだけで、それだけであるように思えます。 しかし、落とし穴があります! それについて話し合いましょう。
実験数に依存
分散を計算するとき、分母には 2 つの数値 (N または N-1) のいずれかを含めることができることがわかります。 ここで、N は実行された実験の数、またはシーケンス内の要素の数 (本質的には同じものです) です。 これは何に依存しているのでしょうか?

テスト数が百単位で測定される場合は、分母に N を入力する必要があります。単位が N-1 の場合です。 科学者たちは非常に象徴的に境界線を引くことにしました。今日、境界線は数字の 30 を通過します。実験が 30 回未満の場合は、その量を N-1 で割ります。それ以上の場合は、N で割ります。
タスク
分散と数学的期待の問題を解決する例に戻りましょう。 中間の数値 12 が得られましたが、これを N または N-1 で割る必要がありました。 実験数は 21 件で、30 件未満であるため、2 番目のオプションを選択します。 したがって、答えは次のようになります。分散は 12 / 2 = 2 です。
期待値
この記事で考慮する必要がある 2 番目の概念に移りましょう。 数学的期待値は、考えられるすべての結果を加算し、対応する確率を乗算した結果です。 取得された値と分散の計算結果は、1 回につき 1 回だけ取得されることを理解することが重要です。 タスク全体、どれだけの結果を考慮しても。

数学的な期待値の公式は非常に単純です。結果を取得し、その確率を掛けて、2 番目、3 番目の結果に同じ値を加算します。この概念に関連するすべての計算は難しくありません。 例えば、期待値の合計は、合計の期待値に等しい。 仕事についても同様です。 そのような 簡単な操作確率論のすべての量でこれができるわけではありません。 問題を取り上げて、学習した 2 つの概念の意味を一度に計算してみましょう。 さらに、私たちは理論に気を取られていました。実践する時が来ました。
もう 1 つの例
50 回のトライアルを実行し、0 から 9 までの数字が異なるパーセンテージで表示される 10 種類の結果が得られました。 これらはそれぞれ、2%、10%、4%、14%、2%、18%、6%、16%、10%、18%です。 確率を取得するには、パーセンテージ値を 100 で割る必要があることを思い出してください。したがって、0.02 が得られます。 0.1など 確率変数の分散と数学的期待の問題を解く例を示しましょう。
算術平均は、小学校で覚えた公式「50/10 = 5」を使用して計算します。
ここで、数えやすくするために、確率を「分割された」結果の数に変換しましょう。 1、5、2、7、1、9、3、8、5、9 が得られます。得られた各値から算術平均を引き、その後、得られた各結果を 2 乗します。 最初の要素を例としてこれを行う方法を参照してください: 1 - 5 = (-4)。 次に: (-4) * (-4) = 16。他の値については、これらの操作を自分で行ってください。 すべて正しく行った場合、すべてを合計すると 90 になります。

90 を N で割って、分散と期待値の計算を続けましょう。N-1 ではなく N を選択するのはなぜでしょうか。 正解です。実行された実験の数が 30 を超えているため、90/10 = 9 となります。分散が得られました。 別の番号を取得した場合でも、がっかりしないでください。 おそらく、単純な計算ミスをした可能性があります。 書いた内容を再確認すると、おそらくすべてが正しい位置に収まります。
最後に、数学的期待値の公式を思い出してください。 すべての計算を行うのではなく、必要な手続きをすべて終えた後に確認できる答えのみを書きます。 期待値は5.48となります。 最初の要素を例として、0*0.02 + 1*0.1... などを使用して、演算を実行する方法だけを思い出してください。 ご覧のとおり、結果の値に確率を乗算するだけです。
偏差
分散と数学的期待に密接に関連するもう 1 つの概念は、標準偏差です。 ラテン文字の sd またはギリシャ文字の小文字の「シグマ」で表されます。 この概念は、値が中心特徴から平均してどの程度逸脱しているかを示します。 その値を見つけるには、分散の平方根を計算する必要があります。

プロットすると 正規分布二乗偏差を直接確認したい場合は、いくつかの段階で実行できます。 画像の半分を最頻値(中心値)の左側または右側に取り、得られる図形の面積が等しくなるように横軸に垂線を描きます。 分布の中央と結果として得られる横軸への投影の間のセグメントのサイズが標準偏差を表します。
ソフトウェア
式の説明と提示された例からわかるように、分散と数学的期待値の計算は、算術の観点から見ると最も単純な手順ではありません。 時間を無駄にしないためには、高等教育で使用されているプログラムを利用するのが合理的です 教育機関- それは「R」と呼ばれます。 統計や確率論から多くの概念の値を計算できる関数があります。
たとえば、値のベクトルを指定します。 これは次のように行われます。<-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
ついに
分散と数学的期待がなければ、将来何かを計算することは困難です。 大学の講義の主なコースでは、その主題を勉強する最初の数か月間ですでに議論されています。 これらの単純な概念の理解が不足し、それらを計算することができないため、多くの学生がすぐにプログラムで遅れをとり始め、後にセッションの終了時に悪い成績を取り、奨学金を剥奪されるのです。
この記事で紹介されているものと同様のタスクを、少なくとも 1 週間、1 日 30 分ずつ練習してください。 そうすれば、確率論のどんなテストでも、無関係なヒントやチートシートなしで例題に対処できるようになります。







