心理学のコース、卒業証書、修士論文の統計計算結果の表には、指標「p」が常に存在します。
たとえば、次のように 研究目的 10代の少年と少女の間での人生の有意義さのレベルの違いが計算されました。
|
平均値 |
マン・ホイットニーの U 検定 |
統計的有意水準 (p) |
||
|
男子(20名) |
女の子 (5人) |
|||
|
目標 |
28,9 |
35,2 |
17,5 |
0,027* |
|
プロセス |
30,1 |
32,0 |
38,5 |
0,435 |
|
結果 |
25,2 |
29,0 |
29,5 |
0,164 |
|
制御の軌跡 - 「私」 |
20,3 |
23,6 |
0,067 |
|
|
制御の軌跡 - 「生命」 |
30,4 |
33,8 |
27,5 |
0,126 |
|
有意義な人生 |
98,9 |
111,2 |
0,103 |
|
* - 差異は統計的に有意です (p≤ 0,05)
右の列は「p」の値を示しており、その値によって、少年と少女の間で将来の人生の意味の違いが有意であるかどうかが判断できます。 ルールは簡単です:
- 統計的有意性のレベル「p」が 0.05 以下の場合、差は有意であると結論付けられます。 下の表では、「目標」指標、つまり将来の人生の意味に関して、男子と女子の違いが顕著です。 女子の場合、この指標は男子よりも統計的に有意に高くなります。
- 統計的有意性のレベル「p」が 0.05 より大きい場合、差は有意ではないと結論付けられます。 以下の表では、最初の指標を除いて、他のすべての指標について、男子と女子の差は有意ではありません。
統計的有意性のレベル「p」はどこから来たのでしょうか?
統計的有意性のレベルが計算されます 統計プログラム統計的基準の計算も併せて行います。 これらのプログラムでは、統計的有意性のレベルに限界限界を設定することもでき、対応する指標がプログラムによって強調表示されます。
たとえば、STATISTICA プログラムでは、相関関係を計算するときに、「p」制限 (たとえば、0.05) を設定できます。これにより、統計的に有意な関係がすべて赤色で強調表示されます。
統計的基準が手動で計算される場合、有意水準「p」は、結果として得られる基準の値を臨界値と比較することによって決定されます。
統計的有意性の水準「p」は何を示しますか?
すべての統計計算は近似値です。 この近似のレベルによって「p」が決まります。 有意水準は次のように書きます。 小数、たとえば 0.023 または 0.965。 この数値に 100 を掛けると、パーセンテージとして p 指標が得られます: 2.3% と 96.5%。 これらのパーセンテージは、たとえば攻撃性と不安の間の関係についての私たちの仮定が間違っている可能性を反映しています。
あれは、 相関係数攻撃性と不安の間の値は 0.58 で、統計的有意水準 0.05 または誤り確率 5% で得られました。 これはいったい何を意味するのでしょうか?
私たちが特定した相関関係は、サンプルで次のパターンが観察されることを意味します: 攻撃性が高いほど、不安も高くなります。 つまり、2 人のティーンエイジャーがいて、1 人がもう 1 人よりも不安が強い場合、正の相関関係がわかっているので、この 10 代の若者は攻撃性も高いと言えます。 しかし、統計上のすべては近似値であるため、これを述べることで、私たちが間違っている可能性があることを認め、誤りの確率は 5% です。 つまり、この思春期のグループでそのような比較を 20 回行ったので、不安を知って攻撃性のレベルを予測する際に 1 つの間違いを犯す可能性があります。
統計的有意性のレベルは 0.01 と 0.05 のどちらが優れているか
統計的有意性のレベルは、エラーの確率を反映します。 したがって、p=0.01 での結果は、p=0.05 での結果よりも正確です。
心理学研究では、結果の統計的有意性について次の 2 つの許容レベルが受け入れられます。
p=0.01 - 結果の信頼性が高い 比較解析または関係の分析。
p=0.05 - 十分な精度。
この記事があなた自身で心理学の論文を書くのに役立つことを願っています。 サポートが必要な場合は、お問い合わせください (心理学のあらゆる種類の仕事、統計計算)。
最近では、ウラジミール ダビドフ氏が Facebook に A/B テストまたは MVT テストに関する投稿を書き、多くの疑問を引き起こしました。
通常、Web サイトで A/B テストまたは MVT テストを実施するのは非常に困難です。 「着陸者」にとってはこれは初歩的なことのように見えますが、「これも同じです、 特別番組、ギグ。
Web コンテンツをテストする場合は、次の点に注意してください。
1. まず、同じ、同じ規模、同じ品質の視聴者を分離する必要があります。 A/A テストを実施します。 オンライン代理店や経験の浅いインターネットマーケティング担当者が実施するテストの大部分は不正確です。 まさに、コンテンツがさまざまな視聴者に対してテストされるためです。
2. 数か月にわたって数十回、できれば数百回のテストを実施します。 1 週間にわたって 2 ~ 3 つのバージョンのページをテストする価値はありません。
3. A と B だけでなく、MVT 形式 (つまり、多くのオプション) でテストすることもできることに注意してください。
4. テスト結果を使用してデータ配列を統計的に分析します (Excel はまったく問題ありません。SPSS も使用できます)。 結果は誤差の範囲内ですか、どの程度逸脱しますか、また時間はどのように依存しますか? たとえば、A/A テストの最初のポイントで、あるオプションが別のオプションから大きく逸脱している場合、これは不合格となり、それ以上テストすることはできません。
5. すべてをテストする必要はありません。 これはエンターテイメントではありません(他に何もすることがない場合を除く)。 マーケティングとビジネス分析の観点から、顕著な結果につながる可能性があるものだけをテストすることは理にかなっています。 そして、その結果を実際に測定できるものでもあります。 たとえば、サイトのフォント サイズを大きくすることに決め、より大きなフォントを使用したページを数週間テストしたところ、売上が増加したとします。 これはどういう意味ですか? したがって、私は何も気にしません(前の段落を参照)。
6. パス全体をテストする必要があります。 つまり、購入ページ (またはサイト上のアクション) を実行してテストするだけでは十分ではありません。最終的なコンバージョン ページにつながるページとステップをテストする必要があります。
コメントで質問がありました:
「勝者はどうやって決まるの? ここでは、直接販売するページの見出しをテストしました。 勝者を宣言するには、A と B の間にどのようなコンバージョンの差がなければなりませんか?
ウラジミールの答えは次のとおりです。
まず、長期にわたって孤立した実験を行う必要があります (統計的評価の基本ルール)。 第二に、すべては必然的に統計と数学に帰着します (そのため、私は Excel と SPSS、または無料の類似物を推奨します) 値の違いが何かを意味する信頼確率を計算する必要があります。 良い記事があります (多くの記事のうちの 1 つ)。 そこで彼らは、Optimizely テストに基づいて GA からトランザクションを取得します。https://www.distilled.net/uploads/ga_transactions.png 、取引(購入)を通常のベル分布と比較し、平均が範囲内にあるかどうかを確認します。 信頼区間エラーhttps://www.distilled.net/uploads/t-test_tool.png
当社からのオファーを受け取りたいですか?
連携開始コンバージョンの増加における統計的重要性の役割: 知っておくべき 6 つのこと
1. まさにその意味

「この変更により、90% の信頼水準でコンバージョンの 20% 増加を達成することができました。」 残念ながら、この記述は、「コンバージョンが 20% 増加する可能性は 90% である」という非常によく似た別の記述とまったく同等ではありません。 それで、それは実際には何についてですか?
20% は、サンプルの 1 つに対するテストの結果に基づいて記録した増加です。 空想や推測を始めると、テストを無期限に続けた場合、この成長が永久に続く可能性があると想像するかもしれません。 しかし、これは、90% の確率でコンバージョンが 20% 増加する、あるいは「少なくとも」 20%、または「約」20% 増加するという意味ではありません。
90% は、コンバージョンが変化する確率です。 言い換えれば、この結果を得るために 10 回の A/B テストを実行し、10 回すべてを無限に実行することにした場合、そのうちの 1 つ (変更の確率が 90% であるため、結果が変わらない場合は 10% が残ります)。おそらく、最終的には「テスト後」の結果を元の変換に近づけることになるでしょう。つまり、変更はありません。 残りの 9 つのテストのうち、一部のテストでは 20% に満たない増加が見られる可能性があります。 他の場合では、結果がこの基準を超える可能性があります。
このデータの解釈を誤ると、テストを「展開」することで大きなリスクを負うことになります。 テストで 95% の信頼水準で高いコンバージョン率が示されると興奮しがちですが、テストが論理的な結論に達するまでは、あまり期待しないほうが賢明です。
2. いつ使用するか
最も明白な候補は A/B 分割テストですが、それだけが唯一のテストというわけではありません。 また、セグメント (オーガニック検索と有料検索からの訪問など) や期間 (2013 年 4 月と 2014 年 4 月など) 間の統計的に有意な差をテストすることもできます。

ただし、この相関関係は因果関係を意味するものではないことに注意してください。 分割テストを実行すると、結果の変化はページを区別する要素に起因することがわかります。 特別な注意残りのページが完全に同一であることを保証するために注意が払われます。 オーガニック検索と有料検索からの訪問者などのグループを比較する場合、他の要因が影響する可能性があります。たとえば、オーガニック検索からは夜間の訪問が多く、夜間訪問者のコンバージョン率は非常に高い可能性があります。 有意性検定は、変化の理由があるかどうかを判断するのに役立ちますが、その理由が何であるかを判断することはできません。
3. コンバージョン率、直帰率、離脱率の変化をテストする方法
私たちが「指標」を見るとき、実際にはバイナリ変数、つまり誰かが目標のアクションを完了したか、しなかったかの平均を見ていることになります。 コンバージョン率が 40% の 10 人のサンプルがある場合、実際には次のようなテーブルが表示されます。

統計的有意性の重要な要素である標準偏差を計算するには、このテーブルと平均が必要です。 ただし、テーブル内のすべての値が 0 または 1 であるという事実により、計算が容易になります。計算に電卓を使用することで、膨大な数値リストをコピーする必要がなくなりました。 信頼確率 A/B テストは、平均とサンプル サイズの知識に基づいています。 これは KissMetrics のツールです。

(重要: このツールは計算で確率分布の片側のみを考慮します。両側を使用して結果を両側有意性に変換するには、100% からの距離を 2 倍にする必要があります (たとえば、片側 95) %は両面90%となります)。
説明には「A/B テスト妥当性ツール」とありますが、コンバージョンを直帰率または離脱率に置き換えるだけで、他の指標の比較にも使用できます。 さらに、セグメントまたは期間の比較にも使用できます。計算は同じになります。
また、多変量テスト (MVT) にも適しています。各変更を元の変更と個別に比較するだけです。
4. 平均請求額の変化をテストする方法
非バイナリ変数の平均値をテストするには、完全なデータセットが必要なので、ここでは状況が少し複雑になります。 たとえば、A/B 分割テストの平均注文額に有意な差があるかどうかを判断したいとします。この点は、ビジネス指標にとってはコンバージョン自体と同じくらい重要ですが、コンバージョンの最適化では省略されることがよくあります。
まず最初に必要なのは、Google Analytics から取得することです 完全なリスト各テスト オプションのトランザクション - A と B (だった、なった)。 最も簡単な方法これを行うには、分割テストのカスタム変数に基づいてカスタム セグメントを作成し、トランザクション レポートを Excel スプレッドシートにエクスポートします。 デフォルトの 10 行だけでなく、すべてのトランザクションがそこに含まれていることを確認してください。

トランザクションのリストが 2 つある場合は、次のようにそれらをツールにコピーできます。
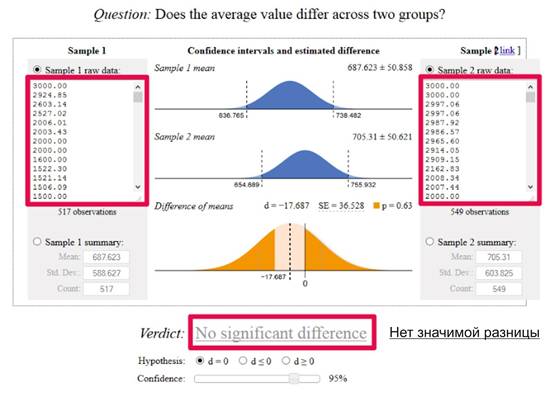
上記の場合、選択したレベル 95% の信頼度はありません。 実際、下のグラフの 0.63 より上の p スコアを見ると、50% の有意性さえないことが明らかです。ページ スコア間の差が純粋に偶然によるものである可能性は 63% あります。
5. A/B 分割テストに必要な期間を予測する方法
Evanmiller.org にはもう 1 つあります 便利なツール変換最適化用 - サンプルサイズ計算機。
このツールを使用すると、「信頼できるテスト結果が得られるまでにどれくらい時間がかかりますか?」という質問に答えることができますが、この答えは推測する価値はありません。

注目すべき点がいくつかあります。 まず、このツールには絶対/相対スイッチがあります。5% の基本コンバージョン率と 6% の可変コンバージョン率の差を調べたい場合は、絶対 1% (6-5=1) になります。相対的には 20 % (6/5=1.2)。 次に、ページの下部に 2 つの「スライダー」があります。 低い方が必要な有意性レベルを担当します。目標が 95% の有意性を達成することである場合、スライダーは 5% に設定する必要があります。 上部のスライダーは、ページに必要な訪問数が十分である確率を示します。たとえば、95% の重要性を見つける確率が 80% になるのに必要な訪問数を知りたい場合は、上部のスライダーを次のように設定します。 80%、下のスライダーを 5% にします。
6.してはいけないこと
分割テストの不適合性を特定する簡単な方法がいくつかありますが、一見しただけでは必ずしも明らかではありません。
A) 非バイナリ順序値の分割テスト
たとえば、目的は、元のグループと変更後のグループの訪問者が特定の製品を購入する可能性に大きな差があるかどうかを判断することです。 3 つの製品に「1」、「2」、「3」というラベルを付け、これらの値を有意性検定フィールドに入力します。 残念ながら、このアプローチは機能しません。製品 2 は製品 1 と 3 の平均ではありません。
B) トラフィック分散設定

テストの開始時に、リスクを冒さないことを決定し、トラフィック分散を 90/10 に設定します。 しばらくして、この変更がコンバージョンに目立った変化をもたらさなかったことを確認し、スライダーを 50/50 に移動します。 ただし、再訪問者は依然として元のグループに属しているため、「変更前」バージョンの再訪問者の割合が高く、コンバージョンに至る可能性が高いという状況になります。 状況はすぐに複雑になるため、信頼できるデータを取得する唯一の簡単な方法は、新規訪問者と再訪問者を別々に調べることです。 ただし、この場合、意味のある結果が得られるまでに時間がかかります。 また、両方のサブグループが有意な結果を示したとしても、どちらか一方が実際により多くの再訪問者を生み出したらどうなるでしょうか? 一般に、テスト中にこれを行ってトラフィック分散を変更する必要はありません。
B) 計画
当然のことのように思えますが、同じ時間帯に収集されたデータを、日中または他の時間帯に収集されたデータと比較しないでください。 特定の時間帯にテストしたい場合は、2 つのオプションがあります。
1. 訪問者のリクエストには通常どおり 1 日中対応しますが、興味のない時間帯にはページの元のバージョンを表示します。
2. 同一内容を比較する – 1 日の前半の変更データのみを確認している場合は、その日の前半の元のデータと比較します。
上記の内容がコンバージョン率の最適化に役立つことを願っています。 独自のノウハウをお持ちの場合は、コメントで共有してください。
有料機能。統計的有意性機能は、一部のプランでのみ利用可能です。 にあるかどうかを確認してください。
から受け取った回答に統計的に有意な差があるかどうかを確認できます。 さまざまなグループアンケートの質問への回答者。 SurveyMonkey の統計的有意性機能を使用するには、次のことを行う必要があります。
- アンケートの質問に比較ルールを追加するときに、統計的有意性機能を有効にします。 比較する回答者のグループを選択して、調査結果を視覚的に比較できるようにグループに分類します。
- アンケートの質問のデータ テーブルを調べて、さまざまな回答者グループから受け取った回答に統計的に有意な差異があるかどうかを特定します。
統計的有意性を表示する
以下の手順に従って、次のようなアンケートを作成できます。 統計的有意性.
1. アンケートに自由回答形式の質問を追加する
結果を分析するときに統計的有意性を表示するには、アンケートの質問に比較ルールを適用する必要があります。
調査設計で次のいずれかを使用すると、比較ルールを適用して回答の統計的有意性を計算できます。 次のタイプ質問:
提案された回答の選択肢が完全なグループに分割できることを確認する必要があります。 比較ルールの作成時に比較用に選択した回答オプションは、調査全体を通じてデータをクロス集計に整理するために使用されます。
2. 回答を集める
アンケートを完了したら、アンケートを送信するコレクターを作成します。 いくつかの方法があります。
統計的有意性をアクティブにして表示するには、比較ルールで使用する予定の応答オプションごとに少なくとも 30 の応答を受信する必要があります。
調査例
あなたは、男性が女性よりもあなたの製品に大幅に満足しているかどうかを知りたいと考えています。
- アンケートに 2 つの多肢選択式の質問を追加します。
あなたの性別は何ですか? (男女)
当社の製品に満足していますか、それとも不満ですか? (満足、不満) - 少なくとも 30 人の回答者が性別の質問に「男性」を選択し、少なくとも 30 人の回答者が性別として「女性」を選択していることを確認してください。
- 「あなたの性別は何ですか?」という質問に比較ルールを追加します。 両方の回答オプションをグループとして選択します。
- 「当社の製品に満足していますか、それとも不満ですか?」という質問表の下にあるデータ表を使用してください。 統計的に有意な差を示す応答オプションがあるかどうかを確認する
統計的に有意な差とは何ですか?
統計的に有意な差とは、統計分析により、ある回答者グループの回答と別のグループの回答の間に有意な差があると判断されたことを意味します。 統計的有意性とは、取得された数値が大幅に異なることを意味します。 このような知識はデータ分析に大いに役立ちます。 ただし、得られた結果の重要性を判断するのはあなたです。 調査結果をどう解釈し、それに基づいてどのような行動をとるべきかを決めるのはあなたです。
たとえば、男性顧客よりも女性顧客からのクレームの方が多いとします。 このような違いが実際にあるのかどうか、またそれに関して措置を講じる必要があるかどうかをどのように判断できるのでしょうか? の一つ 素晴らしい方法あなたの観察を確認することは、あなたの製品が有意であるかどうかを示す調査を実施することです より大きな範囲で男性客も満足。 統計的有意性関数を使用すると、統計式を使用して、製品が実際に女性よりも男性にとってはるかに魅力的であるかどうかを判断できます。 これにより、推測ではなく事実に基づいて行動を起こすことができます。
統計的に有意な差
結果がデータ表で強調表示されている場合は、2 つの回答グループが互いに大きく異なっていることを意味します。 「有意な」という用語は、結果として得られる数値に特別な重要性や有意性があるという意味ではなく、数値間に統計的な差があるということのみを意味します。
統計的に有意な差はありません
対応するデータ表で結果が強調表示されていない場合は、比較されている 2 つの数値に違いがある可能性はあるものの、それらの間に統計的な違いはないことを意味します。
統計的に有意な差がない回答は、使用するサンプル サイズを考慮すると、比較対象の 2 つの項目間に有意な差がないことを示していますが、これは必ずしも有意でないことを意味するわけではありません。 おそらくサンプルサイズを増やすことで、統計的に有意な差を特定できるようになります。
サンプルサイズ
サンプルサイズが非常に小さい場合、2 つのグループ間の非常に大きな差のみが重要になります。 サンプルサイズが非常に大きい場合は、小さな差異も大きな差異も有意なものとしてカウントされます。
ただし、2 つの数値が統計的に異なるからといって、結果の違いが何らかの違いを生むわけではありません。 実用的な重要性。 どの違いが調査にとって意味があるのかを自分で判断する必要があります。
統計的有意性の計算
標準的な 95% 信頼水準を使用して統計的有意性を計算します。 回答の選択肢が統計的に有意であると示された場合、それは、偶然単独で、またはサンプリング エラーにより、2 つのグループ間に差異が生じる確率が 5% 未満であることを意味します (多くの場合、次のように表示されます: p<0,05).
グループ間の統計的に有意な差を計算するには、次の式を使用します。
|
パラメータ |
説明 | |
|---|---|---|
| a1 | 質問に特定の方法で回答した最初のグループの参加者の割合に、このグループのサンプル サイズを掛けたもの。 | |
| b1 | 質問に特定の方法で回答した 2 番目のグループの参加者の割合に、このグループのサンプル サイズを掛けたもの。 | |
| プールされたサンプルの割合 (p) | 両グループの 2 株の組み合わせ。 | |
| 標準誤差(SE) | あなたのシェアが実際のシェアとどの程度異なるかを示す指標。 値が低いほど分数が実際の分数に近いことを意味し、値が高いほど分数が実際の分数と大幅に異なることを意味します。 | |
| 検定統計量 (t) | テスト統計。 特定の値が平均と異なる標準偏差の数。 | |
| 統計的有意性 | 検定統計量の絶対値が平均値からの標準偏差の 1.96* より大きい場合、統計的に有意な差があるとみなされます。 |
*1.96 は、スチューデントの t 分布関数で処理される範囲の 95% が平均の 1.96 標準偏差以内にあるため、95% 信頼水準に使用される値です。
計算例
上で使用した例を続けて、製品に満足していると答えた男性の割合が女性の割合よりも大幅に高いかどうかを調べてみましょう。
1,000 人の男性と 1,000 人の女性がアンケートに参加し、その結果、男性の 70%、女性の 65% があなたの製品に満足していると回答したとします。 70% レベルは 65% レベルよりも大幅に高いですか?
調査からの次のデータを指定された式に代入します。
- p1 (製品に満足している男性の割合) = 0.7
- p2 (製品に満足している女性の割合) = 0.65
- n1 (調査対象となった男性の数) = 1000
- n2 (インタビューを受けた女性の数) = 1000
検定統計量の絶対値が 1.96 より大きいため、男性と女性の差が有意であることを意味します。 女性に比べて、男性はあなたの商品に満足する可能性が高くなります。
統計的有意性を隠す
すべての質問の統計的有意性を非表示にする方法
- 左側のサイドバーの比較ルールの右側にある下矢印をクリックします。
- アイテムを一つ選べ ルールの編集.
- 機能を無効にする 統計的有意性を表示するスイッチを使って。
- ボタンをクリックしてください 適用する.
1 つの質問の統計的有意性を非表示にするには、次のことを行う必要があります。
- ボタンをクリックしてください 曲この問題の図の上。
- タブを開く 表示オプション.
- の横にあるボックスのチェックを外します 統計的有意性.
- ボタンをクリックしてください 保存.
統計的有意性の表示が有効になっている場合、表示オプションは自動的に有効になります。 この表示オプションをオフにすると、統計的有意性の表示も無効になります。
アンケートの質問に比較ルールを追加する場合は、統計的有意性機能をオンにします。 アンケートの質問のデータ テーブルを調べて、さまざまな回答者グループから受け取った回答に統計的に有意な差があるかどうかを判断します。
変数間の関係の主な特徴。
変数間の関係の 2 つの最も単純な特性に注目することができます。(a) 関係の大きさと (b) 関係の信頼性です。
- マグニチュード 。 依存性の大きさは、信頼性よりも理解および測定が容易です。 たとえば、サンプル内の白血球数 (WCC) 値が女性よりも高い男性がいた場合、2 つの変数 (性別と WCC) 間の関係は非常に高いと言えます。 言い換えれば、ある変数の値を別の変数の値から予測できます。
- 信頼性 ("真実")。 相互依存性の信頼性は、依存性の大きさほど直観的ではない概念ですが、非常に重要です。 関係の信頼性は、結論が導き出される基礎となる特定のサンプルの代表性に直接関係します。 言い換えれば、信頼性とは、同じ母集団から抽出された別のサンプルのデータを使用して関係が再発見される (つまり、確認される) 可能性がどの程度であるかを指します。
最終的な目標は、この特定の値のサンプルを研究することであることはほとんどないことを覚えておく必要があります。 サンプルは、母集団全体に関する情報を提供する場合にのみ重要です。 研究が特定の基準を満たしている場合、標準的な統計的尺度を使用して、サンプル変数間で見つかった関係の信頼性を定量化し、提示することができます。
依存関係の大きさと信頼性は、変数間の依存関係の 2 つの異なる特性を表します。 ただし、完全に独立しているとは言えません。 通常サイズのサンプル内の変数間の関係 (つながり) の大きさが大きければ大きいほど、信頼性は高くなります (次のセクションを参照)。
結果の統計的有意性 (p レベル) は、その「真実」(「サンプルの代表性」という意味で) の信頼度の推定尺度です。 より技術的に言えば、p レベルは、結果の信頼性に応じて変化する尺度です。 p レベルが高いほど、サンプル内で見つかった変数間の関係の信頼度が低くなります。 つまり、p レベルは、観察結果の母集団全体への分布に関連する誤差の確率を表します。
例えば、 p レベル = 0.05(つまり 1/20) は、サンプル内で見つかった変数間の関係がサンプルの単なるランダムな特徴である確率が 5% であることを示します。 多くの研究では、p レベル 0.05 が誤差レベルの「許容範囲」と考えられています。
どのレベルの重要性を真に「重要」とみなすべきかを決定する際に、恣意性を避ける方法はありません。 結果が偽として拒否される特定の有意水準の選択は、まったく任意です。
実際には、最終的な決定は通常、結果が事前に (つまり、実験が実行される前に) 予測されたか、さまざまなデータに対して実行された多くの分析と比較の結果として事後的に発見されたかによって決まります。研究分野の伝統。
一般に、多くの分野では、p .05 の結果が統計的有意性の許容できるカットオフ値ですが、このレベルには依然としてかなり大きな誤差 (5%) が含まれることに留意してください。
一般に、p .01 レベルで有意な結果は統計的に有意であるとみなされ、p .005 または p .00 レベルの結果は一般に統計的に有意であると考えられます。 001 は非常に重要です。 ただし、この有意水準の分類は非常に恣意的なものであり、実際の経験に基づいて採用された非公式の合意にすぎないことを理解する必要があります。 特定の研究分野で.
収集されたデータ全体に対して実行される分析の数が増えれば増えるほど、純粋に偶然に発見される重要な (選択したレベルでの) 結果の数が増えることは明らかです。
多くの比較を必要とする一部の統計手法では、この種のエラーが繰り返される可能性が高く、比較の総数に対して特別な調整または修正を行います。 しかし、多くの統計的手法 (特に単純な探索的データ分析手法) では、この問題を解決する方法が提供されていません。
変数間の関係が「客観的に」弱い場合、大規模なサンプルを研究する以外にそのような関係をテストする方法はありません。 サンプルが完全に代表的なものであっても、サンプルが小さい場合、その効果は統計的に有意ではありません。 同様に、関係が「客観的に」非常に強い場合、非常に小さなサンプルであっても、高い有意性で検出できます。
変数間の関係が弱ければ弱いほど、それを有意義に検出するために必要なサンプル サイズは大きくなります。
たくさんの異なる 関係の尺度 変数の間。 特定の研究における特定の尺度の選択は、変数の数、使用される測定尺度、関係の性質などによって異なります。
しかし、これらの尺度のほとんどは一般原則に従っています。つまり、観察された関係を、問題の変数間の「考えられる最大の関係」と比較することによって推定しようとします。 技術的に言えば、そのような推定を行う通常の方法は、変数の値がどのように変化するかを調べてから、存在する全体の変動のうちどの程度が「共通の」(「共同」)変動の存在によって説明できるかを計算することです。 2 つ (またはそれ以上) の変数。
有意性は主にサンプルサイズに依存します。 すでに説明したように、非常に大規模なサンプルでは、変数間の非常に弱い関係であっても重要ですが、小さなサンプルでは、非常に強い関係であっても信頼できません。
したがって、統計的有意性のレベルを決定するには、サンプルサイズごとの変数間の関係の「大きさ」と「有意性」の関係を表す関数が必要です。
このような関数は、「母集団にそのような依存性がないと仮定した場合、特定のサイズのサンプルで特定の値 (またはそれ以上) の依存性が得られる可能性がどの程度あるか」を正確に示します。 言い換えれば、この関数は有意水準を与えることになります。
(p レベル)、したがって、母集団にこの依存性が存在しないという仮定を誤って拒否する確率。
この「対立」仮説(母集団内に関連性が存在しないという仮説)は、通常、次のように呼ばれます。 帰無仮説.
誤差の確率を計算する関数が線形で、異なるサンプル サイズに対してのみ異なる傾きを持つ関数であれば理想的です。 残念ながら、この関数ははるかに複雑であり、常にまったく同じであるとは限りません。 ただし、ほとんどの場合、その形式は既知であり、特定のサイズのサンプルの研究で有意水準を決定するために使用できます。 これらの関数のほとんどは、と呼ばれるディストリビューションのクラスに関連付けられています。 普通 .
実験心理学者は通常、データを収集して研究する前に、データを統計的に分析する方法を決定します。 多くの場合、研究者は統計値として定義される有意水準を ( 以下)これには、非ランダムな要因の影響を考慮できる値が含まれています。 研究者は通常、このレベルを確率表現の形式で表します。
多くの心理学実験では、次のように表現できます。 レベル0.05" または " レベル0.01」 これは、ランダムな結果が一定の頻度でのみ発生することを意味します。 0.05(1回中)または 0.01(100回に1回)。 あらかじめ定められた基準を満たす統計データ分析の結果( 0.05、0.01、あるいは 0.001 であっても)、以下では統計的に有意であると呼びます。
この結果は統計的に有意ではない可能性がありますが、それでもある程度興味深いものであることに注意してください。 多くの場合、特に少数の被験者や限られた数の観察を伴う予備研究や実験では、結果が統計的に有意なレベルに達しない可能性がありますが、さらなる研究では、より正確な制御とより多くの観測値を使用することで、統計的有意性が得られることが示唆されます。観察すると、それらはより信頼性が高くなります。 同時に、実験者は、いかなる犠牲を払ってでも望ましい結果を達成するために実験条件を意図的に変更したいという欲求に細心の注意を払わなければなりません。
2x2 プランの別の例 ジ は、2 種類の科目と 2 種類のタスクを使用して、情報の記憶に対する専門知識の影響を研究しました。
彼の書斎で ジ 数字やチェスの駒の暗記を勉強しました( 変数A) 椅子に座る子供たち レカロ ヤングスポーツそして大人たち( 変数B)、つまり 2x2 計画に従います。 子供たちは10歳でチェスが得意でしたが、大人はチェス初心者でした。 最初のタスクでは、通常のゲーム中と同様に、ボード上の駒の位置を記憶し、駒が削除された後にそれを復元する必要がありました。 このタスクの別の部分では、IQ を決定するときに通常行われる、標準的な一連の数字を記憶する必要がありました。
チェスの遊び方などの専門知識は、この分野に関連する情報を記憶しやすくしますが、数字の記憶にはあまり影響を及ぼさないことが判明しました。 古代のゲームの複雑さにあまり慣れていない大人は、覚えている数字は少ないですが、数字を暗記することには成功しています。
報告書の本文では ジ 提示された結果を数学的に検証する統計分析を提供します。
2x2 計画は、すべての要因計画の中で最も単純です。 要素の数または個々の要素のレベルが増加すると、これらの計画の複雑さが大幅に増加します。







