統計で使用される多くの指標の中で、分散の計算に注目する必要があります。 この計算を手動で実行するのはかなり面倒な作業であることに注意してください。 幸いなことに、Excel には計算手順を自動化できる機能があります。 これらのツールを使用するためのアルゴリズムを見てみましょう。
分散は変動の指標であり、数学的期待からの偏差の平均二乗です。 したがって、平均値付近の数値の広がりを表します。 分散の計算は次のいずれかで実行できます。 人口、そして選択的に。
方法1:人口に基づく計算
一般集団について Excel でこの指標を計算するには、次の関数を使用します。 DISP.G。 この式の構文は次のとおりです。
DISP.G(数値1;数値2;…)
合計 1 ~ 255 個の引数を使用できます。 引数は次のとおりです。 数値、およびそれらが含まれるセルへの参照。
数値データの範囲に対してこの値を計算する方法を見てみましょう。


方法 2: サンプルによる計算
母集団に基づいて値を計算するのとは異なり、サンプルを計算する場合、分母は数値の合計ではなく、1 少ない数を示します。 これはエラー修正の目的で行われます。 Excel ではこの微妙な違いが考慮されます。 特別な機能、このタイプの計算を目的としています - DISP.V。 その構文は次の式で表されます。
DISP.B(数値1;数値2;…)
前の関数と同様に、引数の数も 1 ~ 255 の範囲で指定できます。


ご覧のとおり、Excel プログラムを使用すると、分散の計算が非常に簡単になります。 この統計は、アプリケーションによって母集団またはサンプルから計算できます。 この場合、すべてのユーザー操作は実際には処理する数値の範囲を指定することになり、主な作業は Excel 自体が行います。 間違いなくお金の節約になりますよ かなりの量ユーザーの時間。
変化範囲(または変化の範囲) -これは特性の最大値と最小値の差です。
この例では、労働者のシフト生産量の変動範囲は次のとおりです。第 1 旅団では R = 105-95 = 10 人の子供、第 2 旅団では R = 125-75 = 50 人の子供です。 (5倍以上)。 これは、第 1 旅団の生産量がより「安定」していることを示唆していますが、第 2 旅団には生産量を増加させるための余力がより多くあります。 すべての作業員がこの旅団の最大生産量に達した場合、3 * 125 = 375 個の部品を生産できますが、第 1 旅団では 105 * 3 = 315 個の部品しか生産できません。
特性の極値が母集団にとって一般的でない場合は、四分位または十分位の範囲が使用されます。 四分位範囲 RQ= Q3-Q1 は人口体積の 50% をカバーし、最初の十分位範囲 RD1 = D9-D1 はデータの 80% をカバーし、2 番目の十分位範囲 RD2= D8-D2 – 60% をカバーします。
変動範囲インジケーターの欠点は、その値が形質のすべての変動を反映していないことです。
特性のすべての変動を反映する最も単純な一般的な指標は次のとおりです。 平均 線形偏差
、絶対偏差の算術平均です。 別途オプション彼らから 平均サイズ:
,
グループ化されたデータの場合 ![]() ,
,
ここで、xi は次の特性の値です。 個別シリーズまたは区間分布の区間の中央。
上記の式では、分子の差は法で計算されます。それ以外の場合、算術平均の特性に従って、分子は常に次のようになります。 ゼロに等しい。 したがって、平均線形偏差が統計の実践で使用されることはほとんどなく、符号を考慮せずに指標を合計することが経済的に意味がある場合にのみ使用されます。 これを利用して、たとえば、労働力の構成、生産の収益性、対外貿易売上高などが分析されます。
形質の差異は、平均値からの偏差の平均二乗です。
単純な分散 ![]() ,
,
分散加重  .
.
分散の計算式は次のように簡略化できます。
したがって、分散は、オプションの二乗平均と母集団オプションの平均の二乗の差に等しくなります。  .
.
ただし、偏差の二乗の合計により、分散は偏差についての歪んだ考え方を与えるため、平均はそれに基づいて計算されます。 標準偏差
これは、特性の特定のバリアントが平均値からどれだけ逸脱しているかを示します。 分散の平方根を計算して計算します。
グループ化されていないデータの場合  ,
,
のために バリエーションシリーズ
分散と標準偏差の値が小さいほど、母集団が均一になり、平均値の信頼性 (典型的) が高くなります。
平均線形偏差と標準偏差は名前付きの数値です。つまり、それらは特性の測定単位で表され、内容が同一で意味が似ています。
計算する 絶対的な指標表を使用してバリエーションを検討することをお勧めします。
表 3 – 変動特性の計算 (データの周期の例を使用) シフト生産旅団員)
従業員数 |
インターバルの真ん中 |
計算値 |
|||||
合計: |
|||||||
労働者の平均シフト生産量: ![]()
平均線形偏差: ![]()
生産差異: 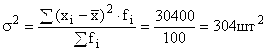
個々の労働者の生産高の標準偏差 平均出力:
.
1 モーメント法による分散の計算
分散の計算には面倒な計算が必要です (特に平均値を表す場合) 多数の小数点以下複数桁あります)。 簡略化された式と分散特性を使用することで、計算を簡素化できます。
分散液には次の特性があります。
- 特性のすべての値が同じ値 A だけ減少または増加した場合、分散は減少しません。
 ,
,
 、その後、または
、その後、または 
分散の特性を使用し、まず母集団のすべての変異を値 A で減らし、次に間隔 h の値で割ることで、等間隔の変異系列の分散を計算する式を取得します。 瞬間の流れ: ,
,
ここで、分散はモーメント法を使用して計算されます。
h – 変動系列の間隔の値。
– 新しい(変換された)値のオプション;
A は定数値であり、最高周波数の間隔の中央として使用されます。 または最も頻度が高いオプション。  – 一次モーメントの二乗;
– 一次モーメントの二乗;
– 二次命令の瞬間。
チームの従業員のシフト生産量に関するデータに基づいて、モーメント法を使用して分散を計算してみましょう。
表 4 - モーメント法を使用した分散の計算
生産労働者のグループ、PC。 |
従業員数 |
インターバルの真ん中 |
計算値 |
||
計算手順:


- 分散を計算します。
2 代替特性の分散の計算
統計によって研究される特性の中には、相互に排他的な 2 つの意味しか持たない特性があります。 これらは代替標識です。 これらにはそれぞれ、オプション 1 と 0 の 2 つの定量値が与えられます。p で示されるオプション 1 の頻度は、この特性を持つユニットの割合です。 差 1-р=q はオプション 0 の頻度です。したがって、
西 |
|
代替符号の算術平均 ![]() なぜなら、p+q=1だからです。
なぜなら、p+q=1だからです。
代替形質の差異
、 なぜなら 1-р=q
したがって、代替特性の分散は、この特性を持つユニットの割合とこの特性を持たないユニットの割合の積に等しくなります。
値 1 と 0 が同じ頻度で発生する場合、つまり p=q の場合、分散は最大 pq=0.25 に達します。
代替属性の分散は、製品品質などのサンプル調査で使用されます。
3 グループ間の分散。 分散加算ルール
分散は、他の変動特性とは異なり、付加的な量です。 つまり、要素の特性に従ってグループに分割された集合体です。 バツ , 得られる特性の分散 yは、各グループ内の分散(グループ内)とグループ間(グループ間)の分散に分解できます。 次に、集団全体にわたる形質の変動を研究するとともに、各グループ内の変動、およびこれらのグループ間の変動を研究することが可能になります。
合計差異形質の変動を測定する でこの変動(偏差)を引き起こしたすべての要因の影響下で全体が変化します。 偏差の二乗平均に等しい 個体値サイン で総平均から計算され、単純分散または加重分散として計算できます。
グループ間分散結果として得られる形質の変化を特徴付ける で因子記号の影響によって引き起こされる バツ、グループ化の基礎を形成しました。 これはグループ平均のばらつきを特徴づけるもので、全体の平均からのグループ平均の偏差の平均二乗に等しくなります。  ,
,
ここで、 は i 番目のグループの算術平均です。
– i 番目のグループのユニット数 (i 番目のグループの周波数)。
– 母集団全体の平均。
グループ内分散ランダムな変動、つまり説明されていない要因の影響によって引き起こされ、グループ化の基礎を形成する要因属性に依存しない変動の部分を反映します。 これは、グループ平均に対する個々の値の変動を特徴づけるものであり、属性の個々の値の平均二乗偏差に等しくなります。 でグループ内の算術平均 (グループ平均) から算出され、各グループの単純分散または加重分散として計算されます。 ![]() または
または ![]() ,
,
ここで、 はグループ内のユニットの数です。
各グループのグループ内分散に基づいて、次のことを決定できます。 グループ内分散の全体平均:
.
3 つの分散間の関係は次のように呼ばれます。 差異を追加するためのルールこれによると、合計分散はグループ間の分散とグループ内分散の平均の合計に等しくなります。
例。 労働者の料金区分(資格)が労働生産性の水準に与える影響を調査したところ、以下のようなデータが得られました。
表 5 – 平均時間当たり生産量ごとの労働者の分布。
№ ピー/ピー |
第4類の労働者 |
第5類労働者 |
|||||
出力 |
出力 |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
で この例では労働者は要素の特性に応じて 2 つのグループに分けられます バツ– ランクによって特徴付けられる資格。 結果として生じる形質 - 生産 - は、その影響 (グループ間変動) と他の要因の両方によって変化します。 ランダム要因(グループ内変動)。 目標は、合計、グループ間、グループ内の 3 つの分散を使用してこれらの変動を測定することです。 経験的決定係数は、結果として得られる特性の変動の割合を示します。 で因子記号の影響下で バツ。 残りの総変動量 で他の要因の変化によって引き起こされます。
この例では、経験的な決定係数は次のようになります。 ![]() または66.7%、
または66.7%、
これは、労働者の生産性の変動の 66.7% が資格の違いによるもので、33.3% が他の要因の影響によるものであることを意味します。
経験的な相関関係は、グループ化とパフォーマンス特性の間の密接な関係を示しています。 経験的決定係数の平方根として計算されます。
経験的な相関比は、 のように、0 から 1 までの値を取ることができます。
接続がない場合は =0 です。 この場合 =0、つまりグループ平均は互いに等しく、グループ間の変動はありません。 これは、グループ化特性要因が一般的な変動の形成に影響を与えないことを意味します。
接続が機能している場合は、=1 になります。 この場合、グループ平均の分散は次のようになります。 合計分散()、つまり、グループ内変動はありません。 これは、グループ化特性が研究対象の結果として得られる特性の変動を完全に決定することを意味します。
相関比の値が 1 に近づくほど、特性間の関連性が機能依存に近づきます。
特性間のつながりの近さを定性的に評価するには、チャドックの関係が使用されます。
例では ![]() 、これは労働者の生産性と資格の間に密接な関係があることを示しています。
、これは労働者の生産性と資格の間に密接な関係があることを示しています。
分散は、データ値と平均値との比較偏差を表す分散の尺度です。 これは統計で最もよく使用される分散の尺度であり、平均からの各データ値の偏差を合計して二乗することによって計算されます。 分散の計算式は次のとおりです。
![]()
s 2 – サンプル分散。
x av - サンプル平均。
n — サンプルサイズ (データ値の数)、
(x i – x avg) は、データセットの各値の平均値からの偏差です。
のために より良い理解数式を使って、例を見てみましょう。 私は料理があまり好きではないので、ほとんど作りません。 しかし、飢えないように、時々ストーブに行き、タンパク質、脂肪、炭水化物で体を飽和させる計画を実行する必要があります。 以下のデータセットは、Renat が毎月料理をする回数を示しています。
分散を計算する最初のステップは、サンプル平均を決定することです。この例では、平均は 1 か月あたり 7.8 回です。 残りの計算は、次の表を使用すると簡単になります。

分散計算の最終段階は次のようになります。
![]()
すべての計算を一度に実行したい人にとって、方程式は次のようになります。
生計数法を使う(調理例)
他にもあります 効果的な方法「生計数」法として知られる分散の計算。 この方程式は一見非常に面倒に見えるかもしれませんが、実際にはそれほど恐ろしいものではありません。 これを確認してから、どの方法が最適かを決定してください。

二乗後の各データ値の合計です。
すべてのデータ値の合計の二乗です。
今は気を失わないでください。 これをすべて表にまとめてみましょう。前の例よりも必要な計算が少ないことがわかります。


ご覧のとおり、結果は前の方法を使用した場合と同じでした。 利点 この方法サンプルサイズ (n) が増加するにつれて明らかになります。
Excelでの分散計算
おそらくすでにご想像のとおり、Excel には分散を計算できる数式があります。 さらに、Excel 2010 以降では、次の 4 種類の分散式が表示されます。
1) VARIANCE.V – サンプルの分散を返します。 ブール値とテキストは無視されます。
2) DISP.G - 母集団の分散を返します。 ブール値とテキストは無視されます。
3) VARIANCE - ブール値とテキスト値を考慮して、サンプルの分散を返します。
4) VARIANCE - 論理値とテキスト値を考慮して、母集団の分散を返します。
まず、サンプルと母集団の違いを理解しましょう。 記述統計の目的は、データを要約または表示して、全体像、いわば概要をすぐに把握できるようにすることです。 統計的推論を使用すると、母集団からのデータのサンプルに基づいて母集団についての推論を行うことができます。 母集団は、私たちにとって関心のあるすべての可能な結果または測定値を表します。 サンプルは母集団のサブセットです。
たとえば、ロシアの大学の学生グループに興味があり、グループの平均スコアを決定する必要があります。 学生の平均成績を計算すると、母集団全体が計算に関与するため、結果の数値がパラメータになります。 ただし、我が国のすべての学生の GPA を計算したい場合は、このグループがサンプルになります。
標本と母集団の分散を計算する式の差が分母になります。 サンプルの場合は (n-1) に等しくなりますが、一般母集団の場合は n のみとなります。
次に、語尾の分散を計算する関数を見てみましょう。 あ、その説明には、テキストと論理値が計算に考慮されると記載されています。 この場合、数値以外の値が発生する特定のデータ セットの分散を計算するとき、Excel はテキストと false のブール値を 0 に等しいものとして解釈し、true のブール値を 1 に等しいものとして解釈します。
したがって、データ配列がある場合、上記の Excel 関数のいずれかを使用してその分散を計算することは難しくありません。

分散確率変数- 特定のスプレッドの尺度 確率変数、つまり彼女 逸脱数学的な期待から。 統計では、分散を表すために表記 (シグマ二乗) がよく使用されます。 に等しい分散の平方根は次のように呼ばれます。 標準偏差または標準スプレッド。 標準偏差は確率変数自体と同じ単位で測定され、分散はその単位の二乗で測定されます。
サンプル全体を推定するために 1 つの値 (平均値、最頻値、中央値など) だけを使用するのは非常に便利ですが、このアプローチでは誤った結論が導き出されやすくなります。 この状況の理由は、値自体にあるのではなく、1 つの値がデータ値の広がりをまったく反映していないという事実にあります。
たとえば、サンプルでは次のようになります。
平均値は5です。
ただし、サンプル自体には、値が 5 の要素は 1 つもありません。サンプル内の各要素がその平均値にどの程度近づいているかを知る必要がある場合があります。 言い換えれば、値の分散を知る必要があります。 データの変化の程度を知ることで、より適切に解釈できるようになります 平均値, 中央値そして ファッション。 サンプル値がどの程度変化するかは、分散と標準偏差を計算することで決定されます。
分散と 平方根標準偏差と呼ばれる分散の値は、サンプル平均からの平均偏差を特徴付けます。 これら 2 つの量のうち、 最高値それは持っています 標準偏差 。 この値は、サンプルの中央の要素から要素までの平均距離と考えることができます。
分散を有意義に解釈するのは困難です。 ただし、この値の平方根は標準偏差であり、簡単に解釈できます。
標準偏差は、最初に分散を決定し、次に分散の平方根を取ることによって計算されます。
たとえば、図に示すデータ配列の場合、次の値が取得されます。

写真1
ここで、差の二乗の平均値は 717.43 です。 標準偏差を取得するには、この数値の平方根を取るだけです。
結果は約 26.78 になります。
標準偏差は、項目のサンプル平均からの平均距離として解釈されることに注意してください。
標準偏差は、平均がサンプル全体をどの程度よく説明しているかを測定します。
あなたが PC アセンブリ生産部門の責任者だとしましょう。 四半期報告書によると、前四半期の生産台数は 2,500 台でした。 これは良いことですか、それとも悪いことですか? このデータの標準偏差をレポートに表示するように要求しました (またはレポートにこの列がすでに存在しています)。 たとえば、標準偏差の数値は 2000 です。部門の責任者であるあなたにとって、生産ラインにはより適切な管理が必要であることが明らかです (組み立てられた PC の数の偏差が大きすぎます)。
標準偏差が大きい場合、データは平均値の周囲に広く分散し、標準偏差が小さい場合、データは平均値の近くに集中することを思い出してください。
4 つの統計関数 VAR()、VAR()、STDEV()、および STDEV() は、セル範囲内の数値の分散と標準偏差を計算するように設計されています。 一連のデータの分散と標準偏差を計算する前に、そのデータが母集団を表すのか母集団のサンプルを表すのかを判断する必要があります。 一般母集団からのサンプルの場合は関数 VAR() と STDEV() を使用し、一般母集団の場合は関数 VAR() と STDEV() を使用する必要があります。
| 人口 | 関数 |
 | DISPR() |
 | スタンドトロンプ() |
| サンプル | |
 | DISP() |
 | STDEV() |
分散 (および標準偏差) は、前述したように、データセットに含まれる値が算術平均の周囲にどの程度分散しているかを示します。
分散または標準偏差の値が小さい場合は、すべてのデータが算術平均付近に集中していることを示します。 非常に重要これらの値は、データが広範囲の値に分散していることを示しています。
分散を有意義に解釈するのは非常に困難です (小さい値、大きい値は何を意味するのでしょうか?)。 パフォーマンス タスク 3データセットの分散の意味をグラフ上に視覚的に表示できます。
タスク
· 演習 1.
· 2.1。 分散と標準偏差という概念を与えます。 統計データ処理の象徴的な名称です。
· 2.2. 図 1 に従ってワークシートに記入し、必要な計算を行います。
・2.3. 計算に使用される基本的な式を教えてください
· 2.4。 すべての指定 ( 、 、 ) について説明します。
・2.5。 説明する 実用的な重要性分散と標準偏差の概念。
タスク2。
1.1. 一般母集団とサンプルという概念を示します。 期待値および統計データ処理のための算術平均記号指定。
1.2. 図2に従ってワークシートを作成し、計算してください。
1.3. (一般母集団とサンプルの) 計算に使用される基本的な式を提供します。

図2
1.4. サンプルで 46.43 や 48.78 などの算術平均値を取得できる理由を説明してください (付録ファイルを参照)。 結論を導き出します。
タスク3。
異なるデータセットを持つ 2 つのサンプルがありますが、それらの平均は同じになります。

図3
3.1. 図 3 に従ってワークシートに記入し、必要な計算を行います。
3.2. 基本的な計算式を教えてください。
3.3. 図 4、5 に従ってグラフを作成します。
3.4. 取得した依存関係を説明します。
3.5. 2 つのサンプルのデータに対して同様の計算を実行します。
オリジナルサンプル 11119999
2 番目のサンプルの算術平均が同じになるように 2 番目のサンプルの値を選択します。次に例を示します。

2 番目のサンプルの値を自分で選択します。 図 3、4、5 と同様の計算とグラフを並べます。計算で使用された基本的な式を示します。
適切な結論を導き出します。
必要なすべての図、グラフ、式、簡単な説明を含むレポートの形式ですべてのタスクを完了します。
注: グラフの構成については、図と簡単な説明を使用して説明する必要があります。
サンプル調査によると、預金者は市内のズベルバンクの預金額に応じて次のように分類されました。
定義する:
1) 変動の範囲。
2) 平均預金サイズ。
3) 平均線形偏差。
4)分散。
5)標準偏差。
6) 貢献度の変動係数。
解決:
この分布系列には開いた間隔が含まれています。 このようなシリーズでは、通常、最初のグループの間隔の値は次のグループの間隔の値に等しいと想定され、最後のグループの間隔の値は次のグループの間隔の値に等しいと想定されます。前回のもの。
2 番目のグループの間隔の値は 200 に等しいため、最初のグループの値も 200 に等しくなります。最後から 2 番目のグループの間隔の値は 200 に等しいため、最後の間隔も 200 になります。値は 200 です。
1) 変動の範囲を属性の最大値と最小値の差として定義します。
預金サイズの変動範囲は1000ルーブルです。
2) 貢献の平均サイズは、加重算術平均式を使用して決定されます。
まずは決めてみましょう 離散量各インターバルの特徴。 これを行うには、単純な算術平均公式を使用して、間隔の中点を見つけます。
最初の間隔の平均値は次のようになります。

2番目 - 500など
計算結果を表に入力してみましょう。
| 堆積量、こすります。 | 預金者の数、f | 間隔の中間、x | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| 合計 | 400 | - | 312000 |
市内のズベルバンクの平均預金額は780ルーブルとなる。
3) 平均線形偏差は、全体の平均からの特性の個々の値の絶対偏差の算術平均です。

区間分布系列の平均線形偏差を計算する手順は次のとおりです。
1. 段落 2) に示すように、加重算術平均が計算されます。
2. 平均からの絶対偏差が決定されます。
3. 結果の偏差に周波数が乗算されます。
4. 符号を考慮せずに重み付き偏差の合計を求めます。
5. 重み付けされた偏差の合計が頻度の合計で除算されます。
計算データテーブルを使用すると便利です。
| 堆積量、こすります。 | 預金者の数、f | 間隔の中間、x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| 合計 | 400 | - | - | - | 81280 |

ズベルバンクの顧客の預金額の平均線形偏差は203.2ルーブルです。
4) 分散は、算術平均からの各属性値の二乗偏差の算術平均です。
分散の計算 間隔行分配は次の式に従って行われます。

この場合の分散の計算手順は次のとおりです。
1. 段落 2) に示すように、加重算術平均を決定します。
2. 平均からの偏差を見つけます。
3. 平均からの各オプションの偏差を二乗します。
4. 偏差の二乗に重み (頻度) を掛けます。
![]()
5. 結果の積を合計します。
![]()
6. 結果の量を重み (度数) の合計で割ります。

計算を表にまとめてみましょう。
| 堆積量、こすります。 | 預金者の数、f | 間隔の中間、x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| 合計 | 400 | - | - | - | 23040000 |







